|
|
|
| Ce document est disponible en: English Castellano Deutsch Francais Turkce Polish |
![[Photo of the Author]](../../common/images/RalfWieland.jpg)
par Ralf Wieland <rwieland-at-zalf.de> L´auteur: J'utilise Linux (depuis la 0.99pl12) pour programmer des simulations environnementales, des réseaux neuronaux et des systèmes aléatoires. Je m'intéresse aussi à l'électronique et j'utilise aussi Linux dans ces domaines. Traduit en Français par: Iznogood <iznogood-at-iznogood-factory.org> Sommaire: |
Etudes démographiquesRésumé:
Cet article traite de la question, « Quelle sera la structure de la
population dans 50 ou 100 ans, si elle continue à se développer de la même
manière qu'aujourd'hui ? » Comme partie de ma tentative de réponse à cette question, je
présente un petit programme QT, que les lecteurs peuvent expérimenter.
Certains pourront sans doute l'utiliser et même
ajouter des extensions au programme.
|
L'immigration et l'intégration des étrangers dans notre pays font partie des sujets de discussion favoris de nos politiciens. Des entreprises basent les profils de leurs produits sur le développement démographique. J'ai lu récemment que les retraités formeraient bientôt la majorité des acheteurs de voitures en Allemagne. Le système de santé, le système de retraites, etc, dépendent tous de la manière dont la population se développe.
De nombreuses recherches ont été réalisées sur ce sujet. Des études poussées ont déjà été publiées. Malgré tout, la plupart des gens ignorent tout des processus qui régissent le développement démographique. Cet article considère moins l'exactitude politique ou scientifique que nos propres expériences. Pourquoi ne pourrions-nous pas regarder, même si c'est d'un oeil amusé, la population dans 50 ou 100 ans ? Que se passe-t-il lorsque des personnes quittent le pays et qu'arrive-t-il lorsque d'autres arrivent ? C'est pour nous permettre d'expérimenter ces possibilités que j'ai développé un petit programme Qt.
La plupart des personnnes se demandent d'où proviennent réellement les « pyramides de population » que l'on voit dans dans les journaux - vous savez, celles qui montrent, par exemple, ce que sera la population dans 50 ans. Sur quelles informations sont basés ces graphiques ?
Si vous y réfléchissez, vous réaliserez que tout dépend du nombre de naissances, du nombre de morts et des mouvements de population dans une zone géographique donnée; en d'autres termes, la migration qui est divisée entre immigration et émigration.
Commençons par la première chose que vous devez savoir pour construire un diagramme démographique : le taux de natalité. Chaque année, un certain nombre de bébés naissent. Le taux de natalité est le nombre moyen d'enfants qu'une femme peut avoir durant sa vie. Ce taux varie en fonction des pays et dépend de nombreux facteurs comme la culture, la situation économique, l'éducation et les traditions. En Allemagne, le taux est de 1.3 enfant par femme.
Certains pays ont une attitude « pro-enfants » alors que dans d'autres, les enfants sont plutôt considérés comme une sorte d'assurance sur les vieux jours. Dans notre cas, le taux de natalité est un point de départ pour le programme, qui peut être défini de 0 à 10 enfants par femme. Cela signifie que nous pouvons ajuster le taux de natalité dans le programme pour étudier différents scénarii.
Le nombre de naissances ne dépend pas seulement du taux de natalité mais aussi du nombre de femmes en âge de porter un enfant. Dans le modèle, le nombre de femmes en âge de porter un enfant (dans le programme, l'âge va de 15 à 45) est simplement cumulé et multiplié par le taux de natalité. Pour calculer le nombre d'enfants nés par an, ce nombre est alors divisé par 45-15=30. Ceci repose sur la supposition que la femme aura, en moyenne, dans sa vie, le nombre d'enfants spécifié par le taux de natalité. Certain d'entre vous pourraient se demander si le taux de natalité est vraiment précis car, après tout, une femme peut avoir 7 enfants, alors qu'une autre peut n'en avoir aucun. C'est un problème de statistiques expliqué dans la littérature spécialisée. Dans notre programme, nous sommes moins concernés par les statistiques exactes et plus par le potentiel d'expérimentation - par exemple, à propos de la question sur ce qui se passerait s'il devenait à la mode d'avoir plus de 3 enfants par famille en allemagne.
Naturellement, là où des enfants naissent, des personnes meurent aussi. Le taux de décès est similaire au taux de natalité, sauf qu'il s'applique à la totalité de la population et non pas seulement aux femmes. (Les hommes, bien sûr, jouent un rôle dans le taux de natalité mais ce n'est pas l'endroit pour en discuter ;-)). L'âge de l'individu est bien sûr un facteur majeur du taux de décès; statistiquement, les personnes les plus âgées sont plus susceptibles de mourir que les plus jeunes. En Allemagne, il existe une table officielle du taux de décès, utilisée par les compagnies d'assurance pour calculer les primes d'assurance sur la vie. Notre programme est basé sur les données de cette table du taux de décès. Vous devrez ajuster ces données pour tous les autres pays.
Notez que dans les pays industrialisés, le taux doit seulement être basé sur l'âge et non sur des facteurs additionnels comme la classe sociale. Néanmoins, comme me l'a expliqué un ami mexicain, ceci ne peut pas être universellement appliqué. Dans notre programme, le taux de décès est seulement basé sur l'âge, donc, si quelqu'un veut inclure des facteurs sociaux, il devra étendre lui-même le programme. Peut-être que quelqu'un souhaitera s'en charger ?
Enfin, la migration doit être aussi prise en compte. En clair, les processus de migration ont toujours joué un rôle important. Par exemple, dans les siècles précédents, la population rurale a eu tendance à migrer vers les villes. Cela ne présentait pas un problème grave dans la mesure où le taux de natalité élevé a compensé les effets de baisse de population. De nos jours, les processus de migration sont différents. Toutefois, la dépopulation rurale est encore un phénomène significatif dans l'Allemagne moderne et provoquera une isolation grandissante de certaines régions.
Le processus complet est autocatalytique et il est renforcé par la dégradation sociale et culturelle. Il est inutile d'avoir des structures pour les enfants dans une zone où peu d'entre eux vivent. En même temps, peu de personnes voudront venir dans une zone où rien n'existe pour les enfants. La même chose se produit pour les structures culturelles. Sans trop entrer dans les détails, il doit être clair que la migration peut avoir beaucoup de causes variées. La chose la plus importante à réaliser dans le cadre du programme est que la structure de l'âge des personnes qui quittent une zone est habituellement différente de celle des personnes qui y viennent. Pour refléter cet état de fait dans le programme, vous pouvez adapter le champ « Distribution (Répartition)» dans le code source « ./demogra/demogra1.cpp » à vos propres objectifs. Cela ne devrait pas être nécessaire pour les premières expériences.
Les champs « Immigration » et « Emigration » sont destinés à entrer ces données. Ces champs prennent des valeurs absolues. Donc si 10000 personnes par an viennent dans une zone, tapez le nombre 10,000 dans le champ Immigration.
Dernier détail et non le moindre, nous vieillissons d'un an chaque année. Pour prendre ceci en compte, la boucle des années donne 41 ans à une personne de 40 ans. Le champ « Step » vous permet d'avancer de plusieurs années en une fois - par exemple, si vous spécifiez 10, le modèle montrera le développement sur une période de 10 ans en une seule étape.
Jetons un petit coup d'oeil à l'interface utilisateur du programme :
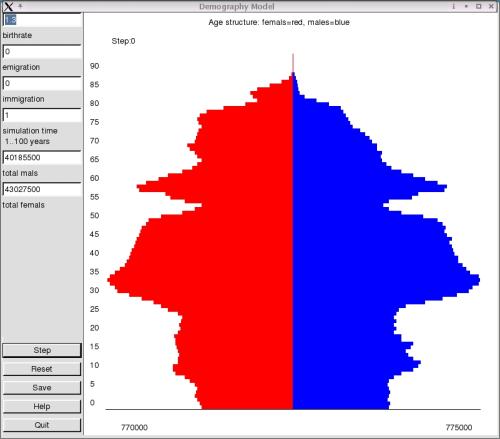
Les champs de saisie décrits ci-dessus sont situés sur la partie gauche de l'écran. Le nombre total d'hommes et de femmes est entré dans le champ correspondant de cette partie de l'écran après chaque étape. Ces champs sont seulement pour l'affichage. De la même manière, toute la zone graphique est dédiée à la visualisation. Les boutons dans la partie inférieure gauche de l'écran sont pour le contrôle de la simulation. Le bouton « Step » exécute une étape dans la simulation. « Reset » remet toutes les données dans leur état initial. Le statut courant du modèle peut être sauvegardé dans le fichier « simulation.dat ». Ce fichier contient le nombre d'hommes et de femmes d'un âge particulier, reflétant le modèle au moment de la sauvegarde. Il est possible d'effectuer une analyse séparée avec ce fichier. Les boutons « Help » et « Quit » sont auto-explicatifs.
La partie la plus basse de la zone d'affichage fournit le nombre maximum d'hommes et de femmes dans tous les groupes d'âge comme valeur de départ. Notez que la taille des barres est en relation avec le chiffre maximum. Ce n'est peut être pas la meilleure solution mais je ne vois pas d'autre alternative pour le moment. Quelqu'un a-t-il une autre idée à ce propos ?
Sinon, la simulation s'explique d'elle-même. Si la donnée est extrême d'une façon ou d'une autre - par exemple, si le nombre d'émigrants est très élevé - des trous vont apparaître dans la pyramide des âges. Ce type de résultat n'est pas réaliste en pratique, l'entrée doit donc être appropriée. D'un autre coté, peut-être qu'un phénomène pathologique, comme le sida, pourrait causer un tel effet. Il se peut qu'une tranche d'âge dans une zone soit décimée par le sida et que le reste de la population s'en aille, laissant la zone déserte.
Le programme est sous licence GPL. La licence TrollTech s'applique pour Qt.
L'installation est très simple. Il faut d'abord télécharger le modèle démographique (voir les références). Utilisez tar -zxvf demographie-0.2.tar.gz pour décompresser le fichier « demographie-0.2.tar.gz ». Démarrez l'installation depuis le répertoire nouvellement créé en utilisant make ou qmake. Les prérequis sont QT3 et gcc. Le programme a été testé avec succès sous SuSE 8.0 et SuSE 8.1, et devrait aussi fonctionner avec d'autres distributions.
Pour démarrer le programme, tapez « ./demographie » sur la ligne de commande. Assurez-vous que « demo.csv » se trouve dans le même répertoire. Ce fichier contient le nombre d'années, les chiffres pour les hommes et les femmes et les taux de décès pour les hommes et les femmes, tous séparés par des virgules. Si vous voulez ajuster les données pour une région particulière, vous le faites dans ce fichier. Dans notre exemple, un journal était la source des chiffres concernant l'Allemagne. Ils n'étaient peut-être pas très précis mais suffisamment adaptés à un but expérimental.
Le programme a été créé pour faire partie d'un système de simulation régionale. Ce système a été conçu pour répondre à des questions tellles que, "comment se développera la population dans une zone bien définie (la zone rurale au nord de Berlin)" ? En particulier, le système a examiné l'arrivée de jeunes familles dans des zones proches de Berlin et le départ des jeunes gens vers les Bundesländer de l'Ouest. Les résultats ont montré de grandes différences d'une région à l'autre. Il existe quelques zones dont la population augmente et d'autres dont la population diminue. Quelques zones, spécialement les plus reculées géographiquement, deviennent de plus en plus clairsemées. Un effet notable est le processus autocatalytique mentionné plus haut.
Toutefois, nous devons être prudents avec ce type de prédictions car toutes les données concernées par un tel processus ne sont pas incluses dans l'évaluation. Par exemple, le phénomène de télétravail signifie que la distance depuis Berlin n'est plus aussi importante qu'il y paraît. Les programmes qui mettent en avant des zones à bon potentiel industriel peuvent créer différents scénarii. En conséquence, les modèles représentent simplement une continuation du statut actuel et ne fournissent que des orientations.
Si nous voulons appliquer le programme dans d'autres zones du monde, nous devons à nouveau considérer les autres processus. Il serait intéressant d'utiliser le programme pour examiner une zone totalement différente, par exemple, les régions rurales du Mexique. De nombreuses nouvelles idées y sont nécessaires. Peut-être que quelqu'un souhaitera analyser ceci plus en détail ou adapter le modèle à d'autres régions ? Je serais ravi d'avoir vos commentaires sur ce sujet.
Je voudrais sincèrement remercier la communauté Linux, qui a développé un si fantastique système. Je veux aussi remercier l'entreprise Troll Tech pour l'admirable Qt et pour l'avoir rendu disponible sous Linux. Et bien sûr un remerciement tout particulier à la FSF pour les nombreux outils, spécialement gcc, sans lequel le travail présenté dans cet article n'aurait pas été possible.
Happy hacking!
|
Site Web maintenu par l´équipe d´édition LinuxFocus
© Ralf Wieland "some rights reserved" see linuxfocus.org/license/ http://www.LinuxFocus.org |
Translation information:
|
2005-02-13, generated by lfparser version 2.52