![[Photo of the Author]](../../common/images2/iznoT2.png)
original in en Iznogood
en to fr Iznogood
Involved in GNU/Linux for a while, I'm now running a Debian system. Despite electronic studies, I've mostly done a translation work for the GNU/Linux community.
I have read that some US universities will help or allow Google to
digitize their library into numeric form. I'm not Google and I haven't
such an university library but I've got some old paper magazine about electronics. And the paper quality wasn't the best: Pages start to fall out, the paper become gray...
Then I decide to digitize it because despite the issues stopped about 10
years ago, some articles are always up to date!
To begin, I needed to feed the data into the computer. A scanner allows
me to do it: after some compatibility check, I bought one, a old used but cheap ScanJet 4300C, and with some internet
navigation, I found the needed settings to configure it.
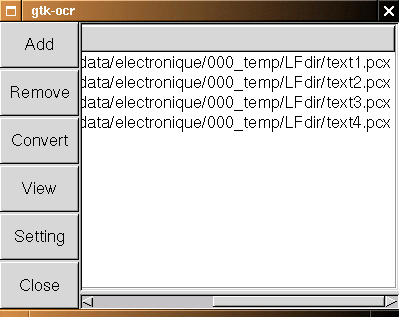
On Debian, I installed sane, xsane, gocr and gtk-ocr as usual with:
apt-get install sane xsane gocr gtk-ocras root.
sane-find-scannerthen I went to /etc/sane.d/ to edit some files:
hp niashand I commented out every thing else.
/dev/usb/scanner0 option connect-deviceand I commented out every thing else.
chgrp scanner scanner0and I add iznogood as user to allow me using the scanner without being root:
adduser iznogood scannerOne reboot, and it was done!
append="hdb=ide-scsi ignore hdb"then
liloto take it into operation.
/dev/sdc0 /dvdrom iso9660 user, noauto 0 0Then I changed scd0 group to cdrom
chgrp cdrom scd0Quite easy.
To continue the process, I needed some software:
sane, xsane, gimp, gocr, gtk-ocr, a text editor, a html editor and some disk space.
sane is the scanner backend and xsane is the graphical frontend.
My idea was to keep the maximum resolution and obtain a 50 MB file for one
page, store it on a harddisk to work on it and when done, store it on
a DVD-ROM.
I put the resolution to 600 dpi, a little bit more brightness and started the
conversion. Since it is on a very old machine (a PII 350 MHz), it takes
some time but I had a good and precise image. I saved it in png format.
Why such a resolution and a 50 MB file? I wanted to keep a maximum resolution
for the archive and for further numeric processing.
Using Gimp I cut the page into graphical images and images containing
just scanned in text.
The graphics were saved in png with a reduced size to fit into a html page
and the text images weren't reduced but changed from color to gray scale (Tools, Colors Tools,
Threshold and Ok) and saved with a .pcx extension for processing with
the optical recognition software.
cat *.txt > test.txtI've got a test.txt and with a text editor I needed to make some adjustments (non french characters removed, words corrected...).
I always remember a maths teacher, when I was young, who told
me this maxim:
"To be lazy, you need to be intelligent".
Ok, I started to be lazy !!!! ;-)
There is some manual parts which are not easy to automate (directory creation,
scanning, gimp cutting and file creation). The rest can be automated.
There is a fabulous English tutorial about bash scripting, ABS (Advanced Bash Scripting Guide),
and I found a french translation.
You can find the English version on www.tldp.org.
This guide allowed me to write some little program. Here is the script:
#!/bin/bash REPERTOIRE=$(pwd) cd $REPERTOIRE mkdir ../ima mv *.png ../ima/ for i in `ls *` do gocr -f UTF8 -i $i -o $i.txt done cd .. mv ima/ $REPERTOIRE cd $REPERTOIRE cat *.txt | sed -e 's/_//g' -e 's/(PICTURE)//g' -e 's/ě/i/g' \ -e 's/í/i/g' -e 's/F/r/g' -e 's/î/i/g' > test.txt
ocr-rppwd will give the directory path to the script, then ima is created outside the directory and all .png files are moved in. All .txt files are then listed, treated with gocr, concatenated in test.txt and had some changes to fit french characters.